



.jpg)

%20(1).png)
%20(1).png)
%20(1)%20(1).png)



.png)
June 23, 2015
Referential integrity and its role in data warehousing: part two
In this pair of tech blog posts, Rob Hawthorne, our head of Microsoft Solutions and Architecture, walks us through the steps needed to implement referential integrity in our data warehouse and keep our DBAs happy. This blog is targeted at business intelligence developers or those with a keen interest in learning new ways of managing metadata in SQL Server.
*** This is part two. Read part one. ***
Re-adding the FK References
This is basically a simple reversal of what we have already achieved. Go ahead and create a package. I named mine 099 - Supplementary Tasks.dtsx, but if you have more than 99 packages you might need a new number J.
Remember I mentioned a while back that I used a secondary table to store the information? In this package we are going to put in a quick check to see if our primary table has the information, and if it doesn’t, use the secondary table.
Add a new Execute SQL Task to the package and use the following query:
query

Set the Result Set to Single Row:

On the Result Set tab, add a new variable to store the results of the query into.

And set the variable type to Int32.
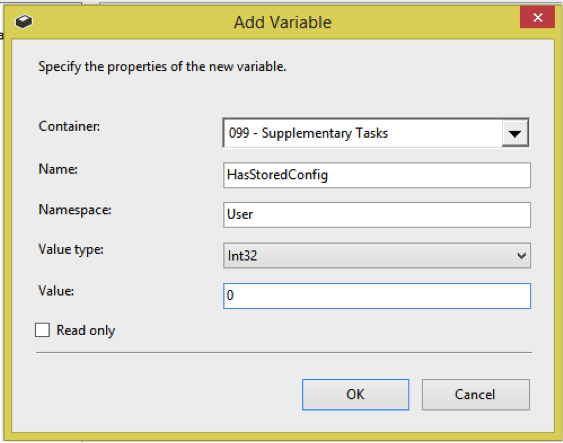
Assign the variable to Result Name 0.

Add 2 more Execute SQL Tasks to the package and set the success of the Check if ForeignKeyReferences has data to the 2 new Execute SQL Tasks.

Right click on the left hand green success flow, and select Edit…

Change the Evaluation operation to Expression and Constraint and enter the following code into the Expression text box:
@[User::HasStoredConfig] > 0

Now right click on the right hand green success flow, and select Edit… andchange the Evaluation operation to Expression and Constraint and enter the following code into the Expression text box:
@[User::HasStoredConfig] < 1

This performs a quick count against our primary table, and if it has rows of data, it will use it as the primary source to build the FK references; if not, it will use the secondary table.
On the left Execute SQL Task open the editor and set the following options:
- Name – Get Config from ForeignKeyReferences Primary
- ResultSet – Full result set
- Connection – To the database that has the primary table of the FK references
- SQLStatement:

On the Result Set tab assign the result set to a new object variable (we need to iterate through it).

On the right Execute SQL Task open the editor and set the following options:
- Name – Get Config from ForeignKeyReferences Secondary
- ResultSet – Full result set
- Connection – To the database that has the primary table of the FK references
- SQLStatement:

On the Result Set tab assign the result set to the same object variable (User::ForeignKeys) as we just created.
Your package should now look similar to the following:

Now we have retrieved the information, we need to build the Foreign Key references statements. So like when we removed them we are going to create a loop to iterate through.
Add a Foreach Loop Container to the package and add the success task from Get Config from ForeignKeyReferences Primary and Get Config from ForeignKeyReferences Secondary to the Foreach Loop Container.
Right click each success constraint and change to Logical OR. One constraint must evaluate to True.

We need to set this, otherwise we will never reach the loop as both tasks would need to execute successfully, yet we only ever execute one or the other. The solid success lines should now change to a dotted arrow.

Like we did earlier, we now set up the enumeration of the object variable and pass the results to an Execute SQL Task.
On the Foreach Loop Container Collection tab set the following options:
- Enumerator - Foreach ADO Enumerator
- ADO object source variable – User::ForeignKeys
- Enumeration mode – Rows in all the tables (ADO.NET dataset only)

On the variable mappings tab, we need to assign all of the columns from the result set into variables. Create the following variables and assign them to their ordinal positions:
- ForeignKeyTableName (String) – Ordinal Position 0
- ForeignKeyName (String) – Ordinal Position 1
- ForeignKeyColumnName (String) – Ordinal Position 2
- TableName (String) – Ordinal Position 3
- ReferencedColumnName (String) – Ordinal Position 4
- OnUpdate (String) – Ordinal Position 5
- OnDelete (String) – Ordinal Position 6

Now add an Execute SQL Task to the Foreach Loop Container.
And set the following options on the Execute SQL Task:
- Name – Add FK Constraints
- ResultSet – None
- Connection – Database that you want to add the constraints too
- SQLStatement –

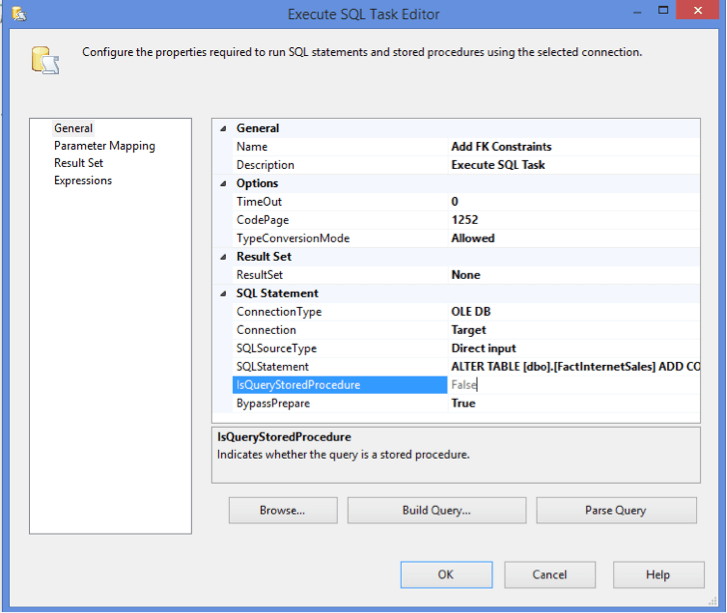
Again the SQLStatement is just a placeholder and we will manipulate it in the Expressions tab.
Add a new expression to the task and set the SqlStatementSource to:
"ALTER TABLE " + @[User::ForeignKeyTableName] + " ADD CONSTRAINT " + @[User::ForeignKeyName] + " FOREIGN KEY( " + @[User::ForeignKeyColumnName] + ") REFERENCES " + @[User::TableName] + "(" + @[User::ReferencedColumnName] + ") ON UPDATE " + @[User::OnUpdate] + " ON DELETE " + @[User::OnDelete]
This should now look similar to:

Again, we switch back to SQL and create a new ER diagram. It will look similar to:
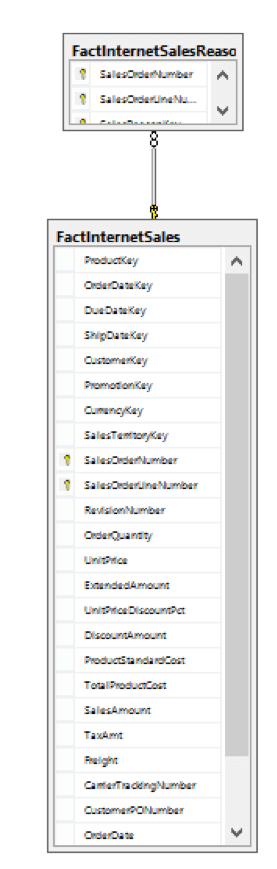
If we switch back to Visual Studio and run our package, and then re-create our diagram, it should look like:

And – ta-da! - we have now successfully recreated our RI!
Some points to note
- This method works on a single column being referenced in the relationship. As the AdventureWorks DW uses the Kimball methodology (i.e. surrogate keys rather than business keys) this is perfectly acceptable. If you wanted to use multiple columns you could either a) build a big string which holds the multiple columns or (and more preferably) b) build a referenced column table that you iterate through when creating the relationships, i.e. a Foreach Loop Container within a Foreach Loop Container.
- If your database does not have any RI defined, you will need to get that information somehow. The easiest method is to create the relationships using the diagramming tool within Management Studio, but remember to name your FK’s carefully, sometimes the default names can be misleading.
- If like AdventureWorks DW you have fact tables which are headers for other fact tables you might want to manage the execution order of dropping and adding constraints. The easiest method would be to add an Order of Execution column which forces the ordering and how the Execute SQL Task executes the statements.
Summary
By using this method we can now manage and maintain the RI within our database. This means we can easily reload dimension tables and recreate the relationships thus keeping our DBA’s happy but more importantly enabling us to produce documentation that will support our business users in understanding the relationships between data sets.
Of course this method can apply to other database types such as transactional systems. Developers can use it as a method of tearing down and rebuilding data sets for test environments, allowing business users to get new copies of data overnight.
I would of course strongly suggest that you add more robust checks to the code, i.e. check the constraint doesn’t exist before attempting to create it as your secondary table may have out of date data. Additionally I haven’t addressed all of the standard best practice things you should do, such as:
- Tidy code structure, i.e. use of Sequence Containers.
- SSIS Logging.
- Alerting/Notifications.
- Backups before changing structure.
But of course everyone is doing all of that already, right?